データ蓄積とは?欠かせないシステムや活用後のデータの流れを解説

CDP(Customer Data Platform、カスタマーデータプラットフォーム)を導入することでデータ取得やデータ蓄積などが可能になります。しかし、データ蓄積といっても具体的にどのようなことなのかイメージしにくいのではないでしょうか?
本記事ではデータ蓄積とは何かや蓄積したデータをどのように活用されるのか、データレイクやデータウェアハウス、データマートについてお話しします。データ分析やDX推進担当者の方はぜひご覧ください。
▼CDPとDMPの違いについてはコチラ
【2024年】CDPとDMPの違いとは?CDPの仕組みや特徴を解説
▼データ活用に必要なデータクレンジングについてはコチラ
データクレンジングはデータ活用をする上で必要!前処理や名寄せを解説
目次
- 1.データレイク・データウェアハウス・データマートを活用したデータ蓄積
- 2. データレイク
- 3. データウェアハウス
- 4. データレイクとデータウェアハウスの違い
- 5. データマート
- 6. データ蓄積する際の注意点
- 7. 蓄積されたデータはどのように活用されるのか?
- 8. CDP(Treasure Data)導入でデータ蓄積を最適化
1. データレイク・データウェアハウス・データマートを活用したデータ蓄積
データ蓄積とは?
データ蓄積とはただ単にデータをデータベースに蓄積するだけではありません。データ基盤としてデータを処理するためにローデータ (元データ)を利用しやすいように加工して処理するというプロセスが含まれています。 データ蓄積のプロセスは以下です。 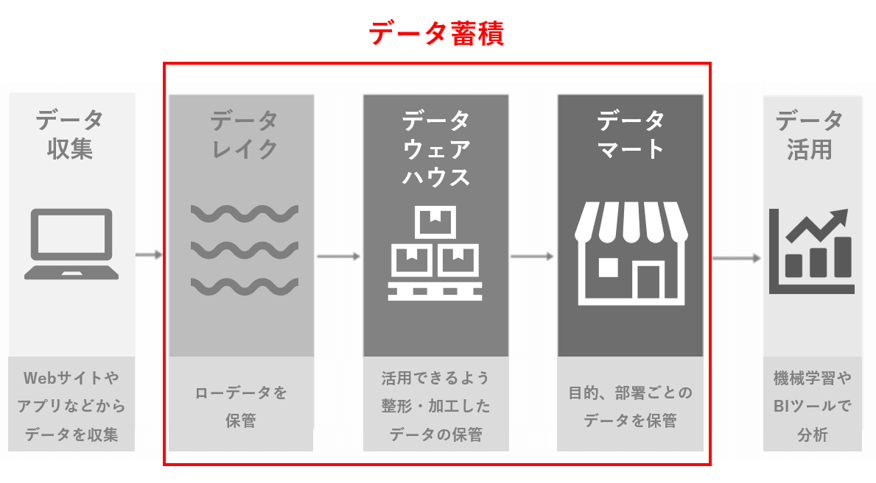
例えば魚をデータに見立てて説明します。最初は魚(データ)が何の目的・用途で活用するかを考えずに海(データレイク)に保存します。その後は活用できるように目的ごとにデータウェアハウスに分けます。最後に用途ごとにデータマートで保管します。こうすることでローデータが活用されやすいように保管することができます。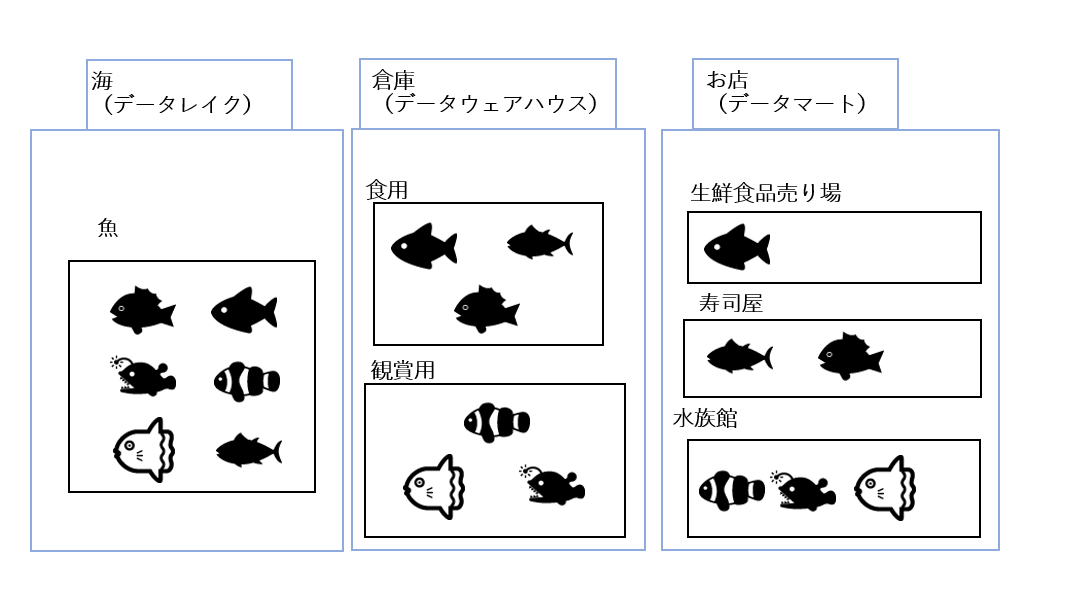
AWS(アマゾンウェブサービス)ですとデータレイクはAmazon S3でデータウェアハウスはAmazon Redshiftです。多くのCDPではデータレイク、データウェアハウスそしてデータマートの役割を一括で担っています。
▼関連サービスサイトはこちら
データ基盤構築(CDP/DMP・BI)サービス
CDP導入前に確認すべき14のポイント
ではなぜデータを集めることが重要なのでしょうか。
なぜデータを集めることが重要なのか
蓄積されたデータには新たなアイデアやイノベーションのヒントが隠れていることがあり、様々な観点の分析を通じて、新しいアプローチや製品の開発・イノベーションにつなげることができます。
また、CDPを利用することで、利用目的に合ったデータを収集・蓄積するための適切なインフラストラクチャやストレージを容易に確保することができ、漏洩リスクやセキュリティの脆弱性を強化しながら、データ利活用の促進をすることができます。
次の章からデータレイクやデータウェアハウス、データマートの詳細を説明します。
2. データレイク
データレイクには取得したままの未加工のデータを格納できます。特に顧客情報や会員情報、購買データなどの構造化されたデータだけではなく画像(jpeg, PNGなど)や音声(mp4など)、PDFなどの非構造データをそのままの形で蓄積できます。
データレイクの特長
データレイクの大きな特長はデータ構造に縛られず、様々な形のデータを格納できる点です。テーブル構造が制限されたRDB(リレーショナルデータベース)では、非構造化データに対応できません。 データレイクではデータを格納する際に決まった形式に整える必要がないため、様々な形のデータを格納することができます。そのため、生データのままストレージに保存しておいて、使いたい時にデータを参照することができます。
データレイクを扱う際の注意点
データレイクはさまざまなデータを蓄積できる反面、用途や管理方法を設けないとデータを集めただけの沼になってしまいます。そうなってしまうと使い勝手が悪くなり「このデータは信頼できるのか」という疑問や「欲しいデータになかなかアクセスできない」という悩みが発生するということが起こりえます。そのため以下のことを意識しましょう。
①データ定義書の作成
データソースや関連する場所、クライアント情報、所有者、データの粒度、種別、形式などのメタデータを一覧化し、どこにどのようなデータが格納されているかを見える化しましょう。
②データレイクを定期的にクレンジングする
データの信頼性を担保するためにデータレイクを定期的にクレンジングして、ノイズとなる不必要なデータを削除しましょう。
具体的には以下のようなものが該当します。
・商品名や顧客名、金額に半角と全角の数字が混在している
・漢数字が使われている ・税込みと税抜きが分かれていない
・日付が西暦と和暦になっている
・数量の単位が違う
・集計に使えるカテゴリーがない
不正確なデータが蓄積されると、分析や意思決定に誤りが生じる可能性があります。データの品質を維持し、適切な整合性を保つためのデータ管理のプロセスを確立することが重要です。
③データのアクセス権限の付与
データはビジネスをより良い方向に導く重要な資産ですがその中に個人情報も含まれています。一歩扱い方を間違うと会社の信頼を損ねてしまいます。
そのため、このデータのアクセス権限は誰なのか?機密情報や個人情報が含まれているデータの保守は担保されているか?データの漏洩のリスクはないか?といったデータの安全性を確保できる仕組みの構築を徹底しましょう。
3. データウェアハウス
データウェアハウスとはデータレイクにある様々なデータから分析や施策で必要なデータを抽出し、時系列でまとめたものです。
データウェアハウスの特長
データウェアハウスの特長はデータ分析の負担が軽減されることです。
データベースのようにデータがシステムごとに様々な形で保存されている場合はシステム間でデータを転送する必要があり時間と労力がかかります。しかしデータウェアハウスは目的ごとにデータが蓄積されているため、円滑にデータ分析を行うことができます。 複雑なクエリや分析を高速に実行することで、大規模なデータセットに対する複雑な分析を効率的に実施することも可能です。
4. データレイクとデータウェアハウスの違い
データレイクとデータウェアハウスはどのように異なるのでしょうか? 詳細はこちらの表をご覧ください。格納される対象データやユーザー、使用用途などが異なります。
5. データマート
データマートとは企業などで情報システムに蓄積されたデータから部門や用途、目的ごとに応じて必要なものだけを抽出、集計し、活用しやすい形に格納したものです。 先ほど紹介したデータウェアハウスは、企業内のデータが構造的にまとめられているため便利ですが容量が大きいため、営業部やマーケティング部などの部門に関するデータを検索したり、抽出するのに手間や時間がかかります。
データマートではデータウェアハウスのデータを部門や用途、目的ごとに細分化して格納しているためデータウェアハウスと比較するとアクセスがしやすいです。社内部門が多くなるにつれてデータマートを構築する必要があるため構築する際は注意が必要です。
データマートの特長
データマートを利用する特長はレスポンスの向上です。 データウェアハウスには場合によっては数TB~ペタバイト級の膨大なデータ量を格納することもあります。その場合、データの分析や追記に時間を要してしまいます。
一方で、データマートに格納されているデータ量は数GB~数百GB程度のデータ量なので、データウェアハウスと比較するとデータの分析や追記に時間がかからず、すぐに分析結果をチェックすることができます。 また、データマートに蓄積されているデータは用途や部署に応じたものなので、集計にかかる時間も短縮でき、分析のレスポンスを高めることができます。
6. データ蓄積する際の注意点
 データを収集し蓄積する過程で、注意すべき点について解説します。
データを収集し蓄積する過程で、注意すべき点について解説します。
①プライバシーとセキュリティリスク
データ蓄積は個人のプライバシーを侵害する可能性があり、個人情報や機密情報を適切に保護して、法的規制や倫理的なガイドラインに従うことが重要です。 また、蓄積されたデータはサイバー攻撃や不正アクセスの標的になる可能性があるため、十分なセキュリティ対策を講じてデータを保護し、データ漏洩や侵害を防ぐ必要があります。
②法的コンプライアンスの遵守
データ蓄積と使用は、地域ごとに異なる法律や規制に大きく影響されます。たとえば、GDPR(一般データ保護規則)やHIPAA(医療情報の保護に関する法律)などが該当します。これらの法律を遵守するための対策を打つ必要があります。
③データ収集・保管のコスト
データを収集・蓄積するためには適切なインフラストラクチャやストレージが必要です。大量のデータを保管することはコストがかかるため、データの価値とコストのバランスを考慮しましょう。
④主観的な判断とデータのバランス
データに過度に依存すると、主観的な判断やクリエイティビティが薄れる可能性があります。データを補完的な情報源として活用し、バランスの取れた意思決定をすることが重要です。
7. 蓄積されたデータはどのように活用されるのか?
蓄積されたデータは実際にどのように活用されるのでしょうか。
例えば、蓄積されたデータは組織や個人の重要な情報源となるので、意思決定をサポートしたり業務の効率向上に役立ちます。 蓄積されたデータから、顧客のニーズや行動パターンを理解することで、より顧客のニーズに合ったサービスの提供も可能になります。
また、データの分析により、業務プロセスの効率を向上させる方法を発見することで無駄を削減できたり、過去のデータを基にリスク要因やセキュリティの脆弱性を特定し、対策を講じることもできます。 蓄積されたデータは以下の流れのように活用され、分析や施策立案に用いられます。
ETL機能などでデータを加工
蓄積されたデータはまず加工されます。先程紹介したデータレイク、データウェアハウス、データマートの順番にデータを処理する際にデータを加工する処理が入ります。その処理のことを「ETL機能」と呼びます 。
ETLとは以下3つの単語の頭文字を取っています。
・Extract(抽出)
・Transform(変換)
・Load(書き込み)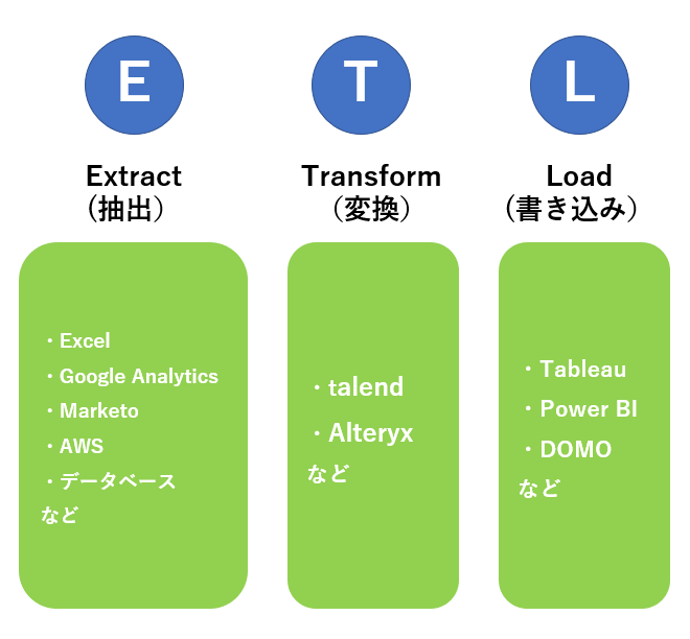 加工される前のデータを抽出し、活用しやすいようにデータを変換し、加工先に書き込みを行う役割を担っています。
加工される前のデータを抽出し、活用しやすいようにデータを変換し、加工先に書き込みを行う役割を担っています。
SQLなどで抽出
次に行うことがデータの抽出です。データマート内で作成したデータから分析や施策立案などの目的に応じて必要なデータを抽出します。基本的にはSQLが書ける人に依頼してデータを抽出しますが、ツールによってはSQLを書く必要なく、操作画面上でデータ抽出ができる場合もあります。
BIツールやMAなどツールと連携して分析・活用
データ分析・活用のフェーズでは抽出したデータを可視化するBIツールでダッシュボードやレポートを作成したり、データをもとに機械学習で顧客の行動を予測したりします。また、SFAやCRM、MAなど各マーケティングツールと連携して新しい考察を導きます。
基本的にはCDPでデータを抽出し、ツールに連携して分析・活用することが主ですが、CDPによってはツール内でAIや機械学習を活用した高度な分析ができます。
BIツールについて詳細を知りたい方はこちらをご覧ください。
8. CDP(Treasure Data)導入でデータ蓄積を最適化
いかがだったでしょうか? 今回はデータレイク、データウェアハウス、データマートを活用したデータ蓄積について紹介しました。 本記事を通してデータ活用を進める上でのデータ蓄積の重要性をご理解いただけたら幸いです。
パーソルプロセス&テクノロジーでは、CDPの導入を検討しているお客様に対し、CDP導入の効果や課題を検証する実証実験(PoC)サービスを展開しています。 データ活用戦略の立案~環境構築・施策実装~運用支援まで一気通貫した伴走型の現場支援、さまざまな業務現場を経験しているメンバーだからこそできる現場主導の生きた知見を強みとしています。
ご興味がある方はこちらからご覧ください。 




