データクレンジングはデータ活用をする上で必要!前処理や名寄せを解説

「これからはじめるDX~人材編~」でDXを推進するにあたって必要な人材やその人材の獲得方法をお伝えしました。 しかし、DX導入には人材確保と同等に意識しなければいけないことがあります。それは自社の所有しているデータの整備です。DX推進前にデータを整備しないとデータ連携ができない、工数を必要以上に割いてしまうなどの壁にぶつかります。本記事ではDXを推進前にデータの整備をしなければいけない理由や具体例を紹介します。DX推進を考えている方にぜひご一読いただきたいと思います。
DXの概要について知りたい方はこちら
DXの導入全般について知りたいからはこちら
DX推進に欠かせない人材について知りたい方はこちら
目次
- 1.データ活用の現状
- 2.これからデータ活用を始めるうえで最初に出てくる課題
- 3.データ活用の問題を解決するためには前処理をすべき
- 4.データの前処理の具体例
- 5.前処理はツールや他社にお願いすることがおすすめ
- 6.まとめ
1.データ活用の現状
AIやITの進歩により大量のデータを取得、保管、処理することが容易になりつつあり、データをビジネスに活用する流れがあります。
データをビジネスに反映させる風潮はあるものの、以下の理由でデータを経営の意思決定に活用できている会社は多くないのが現状です。
・データ活用のイメージが付いていない状態でデータ収集や保管をしているから
・データのインフラが満足に整備されていないから
・データの入力項目が多いなど運用が軌道に乗りにくいから
闇雲にデータを収集するだけではコストや時間、人的リソースが想像以上にかかるため、最初は仮説を立て、その仮説をもとにデータの収集を行う必要があります。データ活用当初は全体像を描くことは難しいため、まずはスモールスタートから始めて仮説・検証のPDCAサイクルをすることをおすすめします。
2.これからデータ活用を始めるうえで最初に出てくる課題
仮説立てをしてデータ収集したものの収集したデータからすぐにビジネスに繋がるインサイトを導くことは難しいケースが多いです。データ活用を行うにあたって多くの企業は以下の課題に遭遇します。
・データの型が揃っていない
・データのフォーマットが揃っていない
・重複データが削除されていない
・データ入力が徹底されていない
・共有キーがないため、他部署とのデータ連携ができない
詳細を解説していきます。
データの型が揃っていない
1つ目はデータの型が揃っていないことです。 データにはそれぞれ「数値型」や「文字型」、「日付型」など型が存在します。見た目は同じ日付でも型が異なると連携することができません。これらのデータを連携・統合するにはデータの型を変換するキャストという作業が発生します。 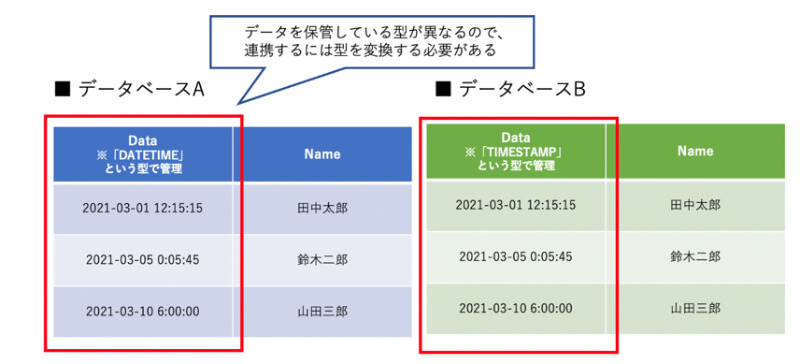
データのフォーマットが揃っていない
2つ目はデータのフォーマットが揃っていないことです。 例えば、A社では日付のデータを年月日の「TIMESTAMP」という形で持っていますが、B社では「UNIXTIME」で所有しているなどがあります。この場合、データ連携・統合する際はデータをキャストする必要があります。 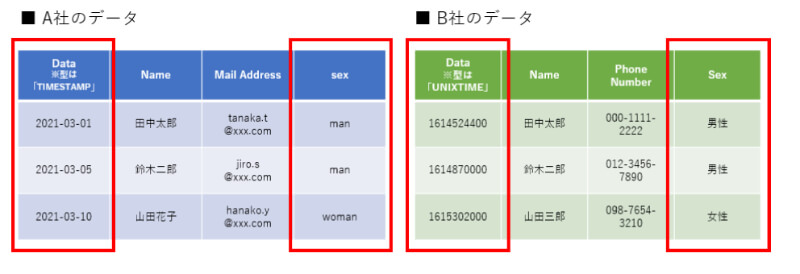
重複データが削除されていない
3つ目は重複データが削除されていないことです。 近年技術の進歩でWeb訪問データやアプリログ、広告ログなど様々なデータが取得できるようになりました。そのため各方面のデータが蓄積されるマスターデータを更新しなければいけません。
更新しないと同じデータが蓄積されデータベースの容量を圧迫したり、正しい顧客情報が不明確になったりします。
データ入力が徹底されていない
4つ目は重複データが削除されていないことです。 商談した顧客情報を営業担当がツールに入力し、マーケティング担当がデータ分析を行うケースは多いと思います。その際、データ入力の運用フローが煩雑、データの記入項目が多いなどの場合はデータの入力が徹底されない可能性があります。
そうなると、データ分析をしようにもデータが入力されていないため分析ができないという問題に陥る可能性があります。
共有キーがないため、他部署とのデータ連携ができない
5つ目は共有キーがないため、他部署のデータと連携ができないことです。 各部署に格納されている顧客の名前は同じだけど同じ顧客IDを振っていないためデータを連携することができないという壁にぶつかる可能性があります。 
3.データ活用の問題を解決するためには前処理をすべき
上述したように、事前にデータを整備・加工することでデータ活用をスムーズに行うことができます。しかし、実際はデータ活用のことも考えてデータ収集、管理している企業は多くありません。
そのため、データ収集後に分析などの活用できるようにするために加工する過程が必要になります。このプロセスのことを「前処理(データプリパレーション)」と呼びます。 
データクレンジングとは
データクレンジングとはデータベースの中にあるデータから入力ミスや文字化け、欠落している、不必要なデータを特定して、一定の基準でデータを修正することです。別名、「データスクラビング」や「データクリーニング」とも呼ばれます。
データクレンジングのメリット
このデータクレンジングを行うことでどのような恩恵を得ることができるのでしょうか?データクレンジングを行うメリットは下記です。
・データ分析の精度を高める
・業務の生産性を上げる
・顧客の信頼度を守る
詳細を見ていきましょう。
データ分析の精度を高める
1つ目はデータ分析の精度を高めるためです。 多くの企業がデータクレンジングを行う目的は自社の顧客管理システムの各種データを統一、整理し、顧客管理作業の効率を上げるためです。データを用いてビジネスを行うには、顧客データベースの定期的なデータクレンジングは必須です。
データ型の異なるものを統一したり、別の場所で保管していたデータを統合・連携したりする際に起こる不整合や、人為的な入力ミスによる質の低下を改善し、汎用性が高いデータ分析環境を構築します。
業務の生産性を上げる
2つ目は業務の生産性を上げるためです。 データベースの整備を行ってデータを扱いやすい状態にすると戦略を立てる際に必要なデータを的確に検索することができます。
また、データ処理やデータ修正などの作業時間を短縮することができるためマーケティングの施策立案やセールスの顧客訪問などメイン業務に注力することができます。そうすることで、営業やマーケティング部門の社員の業務効率が上がります。
顧客からの信頼を守る
不備のあるデータがデータベース内に存在すると顧客データの間違いによるメールの送信先を間違えるなどのインシデントを起こす可能性があります。そうなると顧客に不信感を抱かれ、良好な関係性の構築に支障をきたしてしまいます。データクレンジングに取り組むことで日ごろの入力ミスや誤表記によって生じたデータ不備の修正ができ、顧客からの信頼を守ることができます。
4.データの前処理の具体例
前処理を挟むことで下記のことが可能です。
・最新のデータをリアルタイムで見ることができる環境の構築
・複数のツールを使って取得した重複データをユニーク化して1つのデータへ集約
・データ活用に必要なデータに絞った可視化や分析
この章では前処理の具体例について5つ紹介していきます。
・データの型を揃える
・データのフォーマットを揃える
・重複データのユニーク化
・顧客データの名寄せ
・共有キーを割り振る
データの型を揃える
1つ目はデータの型を揃えることです。 前処理を行うことでデータベースごとのデータの型を変換(キャスト)することができます。データの型を揃えることでBIツールでの分析や四則演算などができるようになります。
データのフォーマットを揃える
2つ目はデータのフォーマットを揃えることです。 データのフォーマットが異なるとダッシュボード作成や四則演算をする際にエラーを吐いてしまいます。そのため、前処理を行ってデータのフォーマットを統一するようにしましょう。
重複データのユニーク化
3つ目は重複データのユニーク化です。 データの鮮度を保つため、多くのデータベースの共通となるマスターデータは定期的にアップデートすることが必須です。ファイルごとに更新日を決めて、最新データを抽出してください。
データ処理を人の手(Excelなど)で行っている企業も少なくありませんが、人為的なエラーを起こしてしまう可能性があるためツールなどを用いることをおすすめします。
顧客データの名寄せ
4つ目は顧客データの名寄せです。 多くの企業では部署やサービス、ツールごとにそれぞれ顧客のデータを蓄積していることが一般的です。そのため、顧客Aさんについての情報が重複している際、その情報がすべて同じ顧客Aさんのものであると判断できないことがあります。
このような状態では顧客一人ひとりに合わせた1to1でのマーケティングの実現は難しいため、散らばっている同一顧客のデータを1つにまとめる必要があります。
これを名寄せといいます。 以下の図をもとに名寄せの説明をします。
山田太郎さんの住所や電話番号、メールアドレスなどは同じだけど会社名だけ異なります。このような場合、別の人物と見なされてしまうため、名寄せのルールを決めてそれに則した人物を同一として判定できます。
今回のルール
名前と電話番号、名前とメールアドレスの組み合わせが同じ人物は同一人物と見なす (データの更新日が最新のものを取得する。) 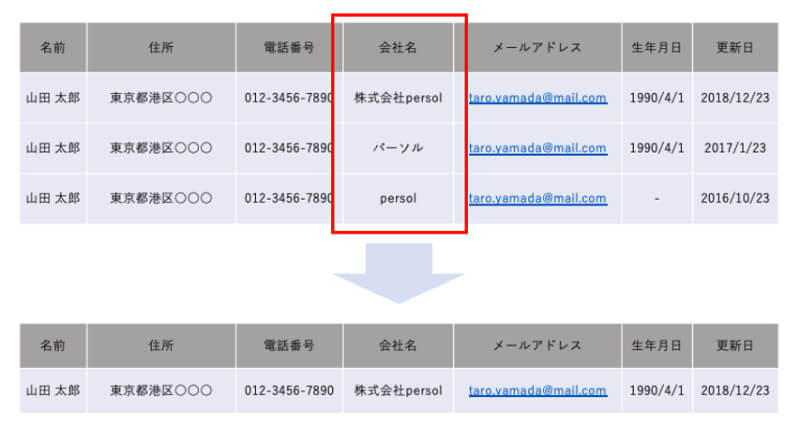
共有キーを割り振る
5つ目はデータの共有キーの割り振りです。 データベースごとに共通している項目(名前や電話番号、メールアドレスなど)をもとに一意のIDを割り振ります。このIDをもとに様々な場所に散らばっているデータを連携することができます。
3つのテーブルが連携・統合される例
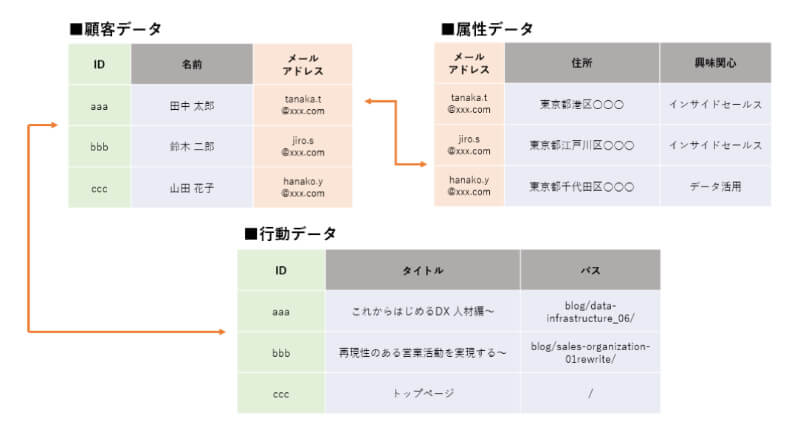
IDを共有キーとして連携されたテーブルの例
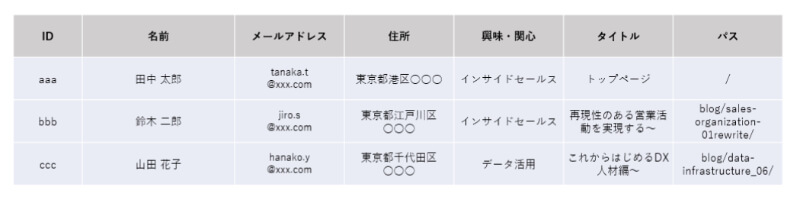
5.前処理はツールや他社にお願いすることがおすすめ
先述したように前処理はデータ活用を行う上で欠かせません。 前処理は主に下記の2つのパターンがあります。
・ツールを導入して行う
・手動で行う
ツールを導入して行う
最近、AIを搭載し、機械学習によってデータを整形してくれるようなツールがあります。これらのツールを活用することによって、負担なくデータを加工できる状態に変換・統合することも可能です。もしツールを導入する際には、何のためにデータを加工するのかという当初の目的を見失わないようにしましょう。 データ活用に欠かせないCDPについて知りたい方はこちらをクリックしてください。 
人の手で行う
手動で行う際はデータベースを操作するSQLやRなどのプログラミング言語を活用して、デフォルト値の設定や外れ値の除外、データの集計や分割、紐づけを行います。
こちらは主にエンジニアやプログラマが行いますが、工数が想定以上に掛かります。社内で行う場合は彼らが並行しているタスクの進捗管理をしながらする必要があります。
もし社内にエンジニアやプログラマがいない、また不足している場合は派遣や業務委託など外部のリソースを利用して実施しましょう。一時の人材不足を補填するにはアウトソーシングが効果的です。 内部との連携が円滑に取れず、データの前処理に失敗することも散見されるのでアウトソーシング先の選定には注意しましよう。
データを活用するまでの道のりは長いですが、1つずつ着実に進めることが成功への道です。
6.まとめ
いかがだったでしょうか? 今回はデータ活用を行う際に抱える課題とその解決策である前処理やデータクレンジングについて紹介しました。 本記事を通してデータ活用を円滑に進めていただけますと幸いです。 パーソルプロセス&テクノロジーでは、CDPの導入を検討しているお客様に対し、CDP導入の効果や課題を検証する実証実験(PoC)サービスを展開しています。ご興味がある方はこちらからご覧ください。 




